
Reálný datový soubor
Nyní si můžeme ukázat výpočet
rozdělení pravděpodobnosti údajů z měření skutečných dat. Tyto údaje, které jsou
obtížně zpracovatelné standardními statistickými způsoby, pocházejí z životního prostředí. Jsou to obvykle
hodnoty z výsledků chemických analýz koncentrací nebo klinické praxe. Jednou z moderních technologií pro tento účel
jsou pasivní vzorkovače (SPMD), které se používají k měření kontaminací jak půdy,
vody i vzduchu. Pomocí nich můžeme měřit velké komplexy kontaminantů, jako jsou perzistentní
organické polutanty (POP), kovy a různé toxické látky. Všechna tato měření mají velkou
nevýhodu, nelze je vyhodnocovat pomocí standardních statistických metod. Jsou velmi
zašuměná, ale přesto nesou důležité informace!
Existují zde dva typy distribučních funkcí globální a lokální.
Existují zde dva typy distribučních funkcí globální a lokální.
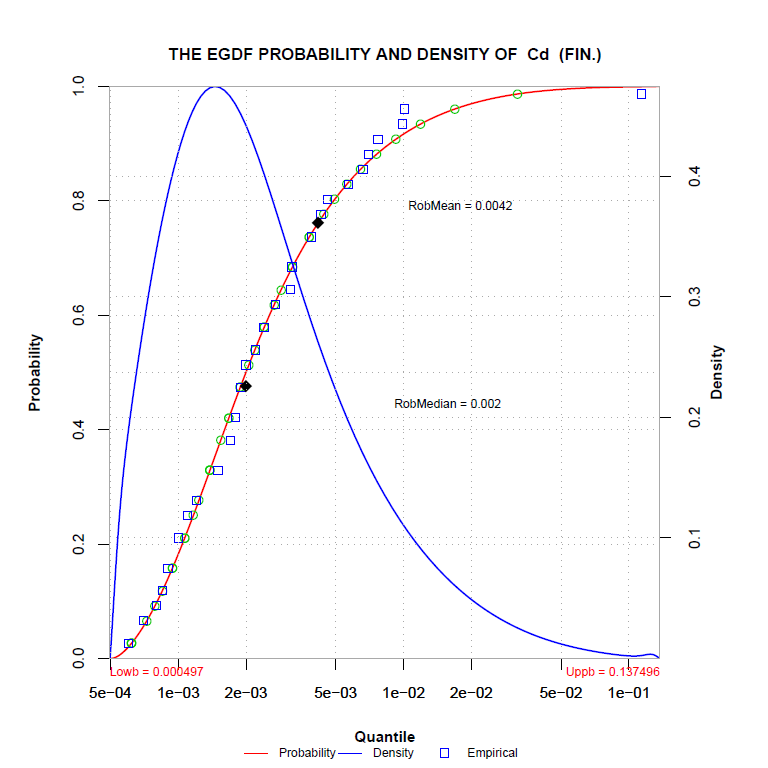
Odhad pomocí globální distribuční funkce je založen na myšlence, že data jsou v zásadě homogenní.
Funkce hledá jedno hlavní maximum - hlavní homogenní shluk, ale některé okrajové body může označit jako narušení
homogenity. Takto získáme kompletní globální pohled na data s odlehlými body na obou stranách intervalu.
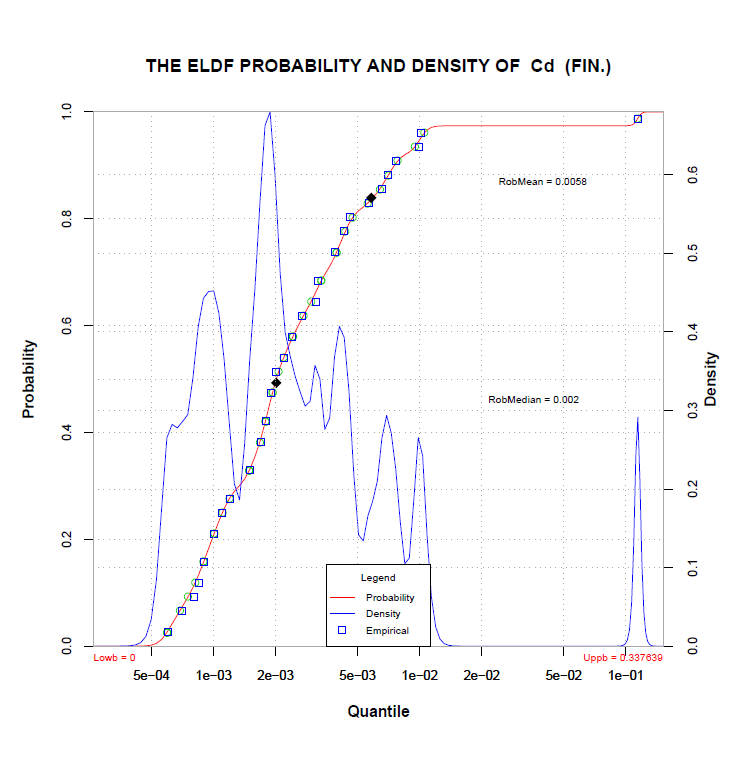
Lokální distribuční funkce odhaluje vnitřní strukturu datového souboru a přes extrémy
funkce hustoty popisuje soubor pomocí vnitřních sub intervalů. Tím umožňuje rozdělit skupiny dat
nezávisle na jiných předpokladech. Rozdělení na shluky je dáno matematickou funkcí nikoliv
předpoklady o charakteru datového souboru!